
From the start, Wexler was designed for high-stake legal matters: vast document sets, unpredictable formats, and zero tolerance for data loss. We remain focused on scale, accuracy, and evidentiary integrity.
As Wexler’s adoption has expanded across global law firms, the meaning of scale has scaled too. The most document-heavy areas of practice (think complex construction disputes, regulatory investigations, class actions) can often result in hundreds of thousands of files which need sorting.
These matters combine structured corporate data with unstructured contemporaneous evidence (including email chains, medical records, and decades of filings). Even a single misread date or missing metadata field can distort the evidentiary record and factual direction of the matter.
In other words, litigation data is uniquely complex. Here’s how we’ve built Wexler’s ingestion and file management layer to keep pace with that reality.
The problem: legal evidence is not tidy data
Litigators work with evidence, not tidy datasets. In one week, a litigation team might upload:
- Expert witness bundles for a product liability trial
- Regulatory correspondence and disclosure logs
- Historic email chains for discovery
- Financial models and presentations from corporate clients
- Transcripts from depositions or parliamentary hearings
Each piece of evidence might originate from a different source, such as client hard drives, Relativity exports, court filings and emails. Each behaves differently when processed. Some are PDFs, others scans or handwritten notes.
Lawyers need a platform that instantly understands this disparity of data, without user preprocessing and human fine-tuning.
That’s what Wexler does.
The challenges Wexler solves
Diversity and size
A matter could have:
- .pst, .msg and .eml files with multiple nested attachments
- Multi-page TIF scans
- Redacted PDFs and handwritten medical charts
- Zipped archives within zipped archives
Wexler handles both volume and diversity, expanding attachments and normalising structures so the full record becomes accessible at once.
Context preservation
In litigation, relationships between documents (who sent what, when, and in what sequence) are as important as the contents themselves. Once that link breaks, reconstruction becomes near impossible.
Wexler maintains those relationships throughout ingestion, so the story remains intact.
From documents to facts
AI models perform best on structured data. Wexler’s ingestion layer converts raw documents into discrete, timestamped facts, linking entities, events, and dates.
This transforms unstructured files into verifiable data that can be searched, compared, or analysed immediately.
How we built ingestion for litigation
We designed the document processing pipeline so litigators never need to think about file handling. Wexler turns the raw files sent from the client into data that’s structured, traceable, and query-ready.
We do this through:
1. Adaptive parallel ingestion
Most upload systems operate sequentially or with fixed concurrency. We built an adaptive scheduler that tunes parallelism by file size, type, and server load. For example, a 100-page PDF and a 20 MB .msg with nested attachments are handled differently. That means large matters upload consistently without bottlenecks or timeouts, maintaining full integrity across tens of thousands of documents.
2. Reliable recovery
Browser uploads will always have limits so we’ve designed Wexler to work within them safely. If your connection drops or the upload is interrupted, anything already received stays intact. You can retry the upload without risk of duplication or data loss. Our deduplication scanner ensures consistency across every batch.
For high-volume or long-running uploads, we’re developing a hardened desktop uploader for full resumability and enterprise-grade reliability at scale.
3. Multi-format normalisation
Wexler can ingest dozens of document formats, including (obviously) Word, PDF, Excel, PowerPoint, TIF, ZIP, .msg, .pst, .eml, and image sets. Internal parsers detect and expand nested attachments, preserve structure, and handle malformed or partial files. You just drag, drop, and Wexler takes it from there.
4. OCR and handwriting tolerance
OCR is often treated as a bolt-on, or something eDiscovery teams need to do before documents can be analysed. For any litigation matter, it’s table stakes to offer this as part and parcel of the software. Wexler uses state-of-the-art OCR to parse any text, including handwriting. When a document mixes typed and handwritten text, both are captured, classified, and confidence-scored for later review. This includes poorly scanned, annotated, edited documents as well as medical records (prevalent in product liability lawsuits), with doctor’s handwriting!
5. Fact-level extraction
This is where ingestion becomes intelligence. Every processed document is decomposed into facts: discrete, timestamped statements with traceable provenance. Entities, events, and roles are linked.
Here’s a regulatory filing parsed into over 350 individual facts, each relevance-scored and tied back to its line reference.
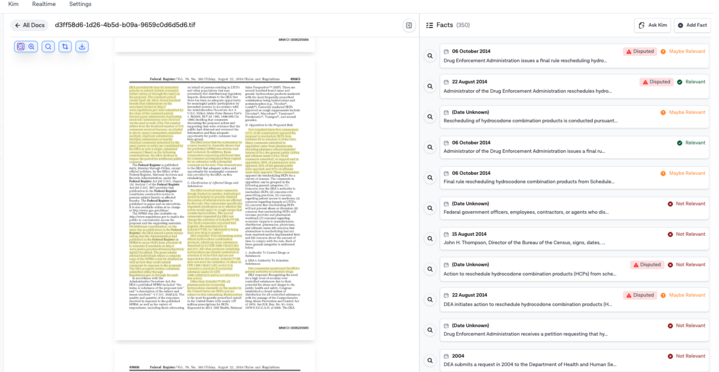
6. Real-time visibility
Every file shows its exact status (uploaded, validating, extracting, indexing) in real time. Large cases display summary dashboards and smaller uploads show per-file progress.
Document acceptance rate: 99.93%* (volume of accepted vs rejected files in last 30 days)
What this means for litigators
Evidence is no longer a logistics problem. You can upload the entire discovery record at once. Wexler handles every format, layer, and relationship.
No context window challenges. This processing into ‘facts’ which can then be analysed through the product means Wexler can attack vast datasets with the same accuracy, quality and retrieval as minute ones.
Insight is immediate. Documents are ingested as structured facts, search, chronology, and entity analysis work instantly, so there are no indexing delays or manual tagging.
Collaboration scales. When multiple teams upload or review in parallel, Wexler merges and reconciles states. Conflicts are resolved intelligently, not by overwriting.
What this means for law firms
AI initiatives in law often fail when data ingestion isn’t solved first. Training or prompting models on unstructured or inconsistent data produces unreliable results.
Wexler provides the foundation that litigation workflows need:
- Consistent structure. Facts, entities, and timelines are extracted from every document type.
- Provenance. Every token of output is traceable to an original file and line.
- Scalability. Ingestion performance keeps up with model throughput.
- Compliance. Metadata and access logs preserved end-to-end for regulatory audit.
In short: clean, structured, and lawful data at scale.
Lessons learned
What we know now:
Variability and volume drive complexity. Not only do you need to be able to handle 100,000 uniform PDFs, you also need to be able to handle 10,000 different formats. Design for entropy.
Push compute to the right layer. Browsers are for interaction, not computation. Server-side orchestration gives reliability and consistency across devices.
Observability is the foundation of optimisation. Every improvement came from live upload feedback. Without tracing, scaling is guesswork.
What’s next?
Our next phase of work focuses on three things:
More scale. Optimising ingestion to handle millions of files per matter without performance loss.
More formats. Extending support beyond documents to include audio, video, and mixed media evidence.
More integrations. Direct connections to where evidence actually lives, from email and messaging archives to cloud storage and enterprise platforms.
From cross-border disputes to competition investigations to multi-party claims, the common challenge is thousands of disparate documents that need to be converted into structured, reliable evidence. That’s the layer Wexler automates. Get a demo.